Whenever I’ve made use of hooks I made basically an /events on my side and saved all of the data that was pushed. Only after it was saved was it processed.
Besides being able to replay, have a log, etc. that also allowed me to progressively handle more events and then retroactively process them if needed.
The downside of not being able to capture events if your service is down remains, however.
But that can be mitigated by either running it is as a microservice, or simply just spinning up a separate instance of the application that’s just for the hooks.
–
There are two benefits of this:
-
You will be able to “replay” them.
If you store the payload of the calls, when there is a failure, or if you have not implemented a specific action, you will be able to “replay” the hook.
-
You have an additional source of data.
If, for instance, you add webhooks for a payment provider, they will call it for many different events. This gives you an insight on the health of your payments. It will then be easier to combine the data from your platform with the events on your payment provider.
Here’s an early implementation of this from Supplybunny:
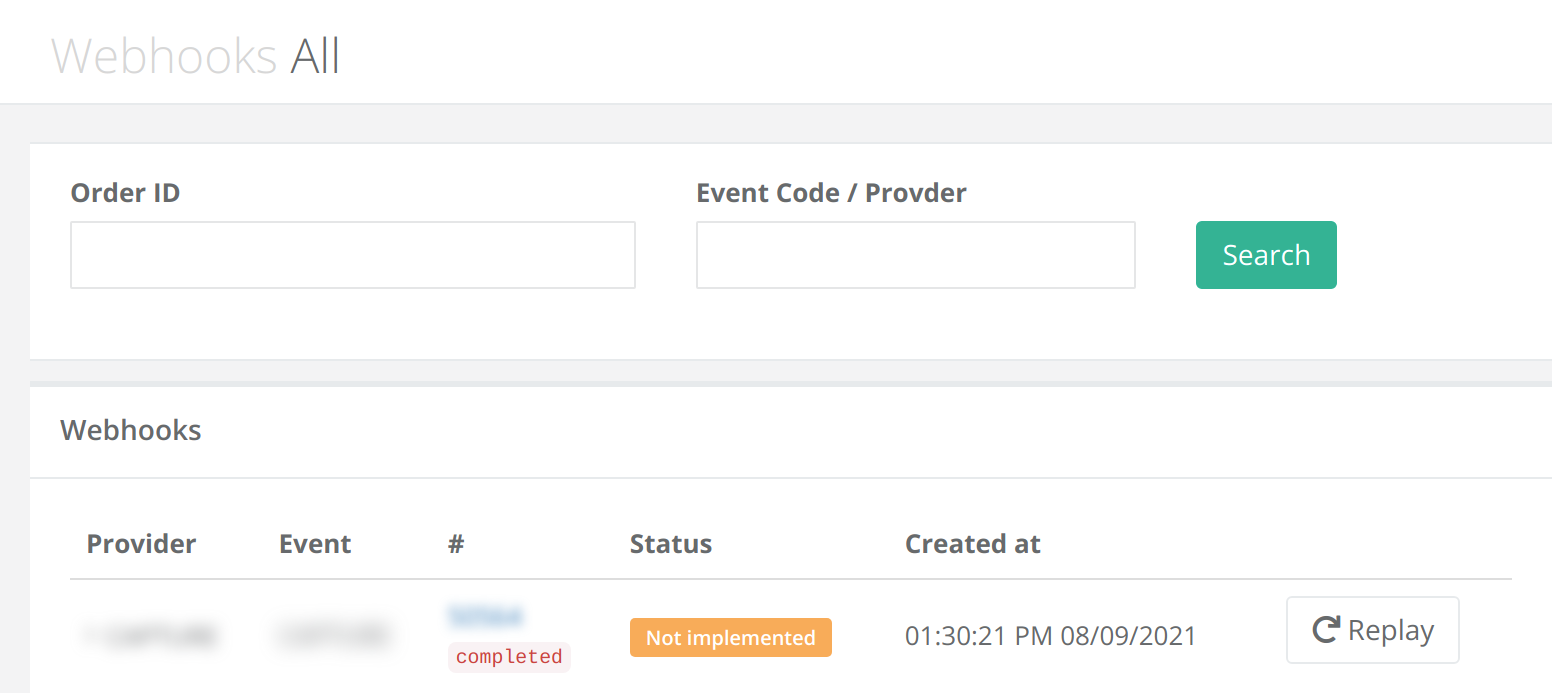
The # column is the order reference. All the providers I dealt with had a merchant reference in the same place for all events. The completed below it is the status of that order.
The status column contains Not implemented meaning it’s for an event that I don’t have the hook for yet.
The row can be expanded to view the entire payload.
The replay button would have called the webhooks service in exactly the same way as the webhook endpoint.